
本文翻译自英文原文的部分内容:From not working to neural networking (2016 The Economist )
人工智能(AI)是如何从问世之初的狂妄自大、令人失望,突然变成当今最热门的技术的?这一概念首次出现在1956年的一份十分重要的研究计划书中。该计划书是这样写的:“只要精心挑选一群科学家,让他们一起研究一个夏天,就可以在以下方面取得重大进展–使机器能够解决目前只有人类才能解决的那些问题。”这看法可以说是过于乐观了,尽管AI研究偶有进展,但它在人们心目中只是“言过其实”的代名词,以至于研究人员基本上会避免直接使用这个概念,转而用“专家系统”或者“神经网络”代替。而“人工智能”的平反和当前的热潮可追溯到2012年的一个叫ImageNet Challenge的在线竞赛。
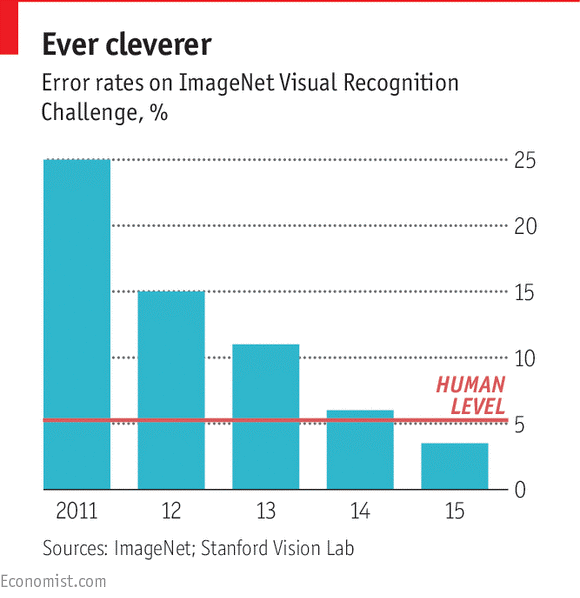
ImageNet是一个在线数据库,包含数百万张图片,全部由人工标记。每年一度的ImageNet Challenge竞赛旨在鼓励该领域的研究人员在计算机自动识别和标记图像方面进行比拼,并展示最新的进展。他们的系统会首先使用一组给定正确标记的图像进行训练,然后接受挑战去标记之前从未见过的测试图像。在随后的研讨会上,获胜者会分享和互相讨论他们的技术。2010年,优胜系统标记图像的准确率为72%(人类的平均准确率为95%)。而在2012年,由多伦多大学教授杰夫·辛顿(Geoff Hinton)领导的一支团队,凭借一项名为“深度学习(deep learning)”的新技术大幅提高了准确率,达到了85%。后来在2015年的ImageNet Challenge竞赛中,这项技术的准确率进一步提升至96%,首次超越了人类。
2012年的比赛结果被理所当然地视为一次突破,但蒙特利尔大学计算机科学家约书亚·本吉奥(Yoshua Bengio)说,这一突破依赖于“与已有的技术结合”。也因此本吉奥和辛顿等人被视为深度学习的先驱。从本质上来讲,这项技术通过强大的计算能力和大量的训练数据,复兴了AI问世之初的一个旧想法,也就是人工神经网络(Artificial Neural Network, ANN)。这些人工神经网络是受生物学启发而形成的人工神经元或细胞网络。
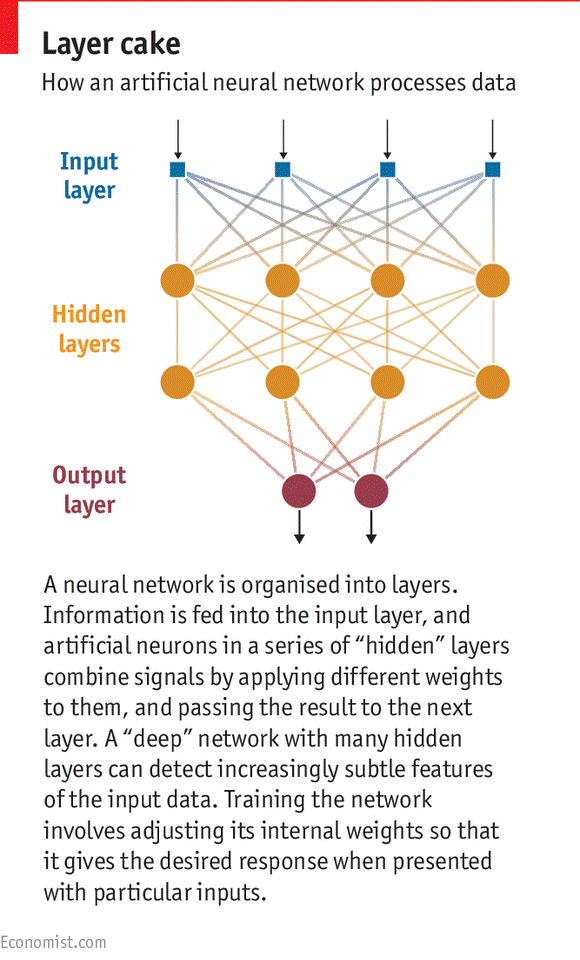
在生物大脑中,每个神经元都可以被其他神经元触发,并将信号输入给它而其自身发出的信号又会触发其他神经元。一个简单的ANN包含一个向网络输入数据的神经元输入层,与一个输出结果的输出层,也许还有两三个处理信息的中间隐藏层(实际上,ANN完全是在软件中模拟生成的)。网络中的每个神经元都有一组“权值”和一个控制其输出启动的“激励函数”。神经网络的训练涉及调整神经元的权值,使特定的输入产生我们所期望的输出(见下图)。20世纪90年代初,ANN开始取得某些可实用的结果,比如识别手写数字。但如果让它们去完成更加复杂的任务,就会遇到麻烦。
在过去10年里,一些新技术和对激励函数的简单调整,使训练深度网络成为可能。同时,互联网的崛起使数十亿的文档、图片和视频可用于训练。这一切都需要强大的数字运算能力。上述强大运算能力的实现是在2009年前后,得益于几支AI研究团队意识到专门用来在PC和游戏机上产生精细图像的图形处理单元(GPU)也非常适合运行深度学习算法。斯坦福大学的一支AI研究团队发现,GPU可以使其深度学习系统的运行速度加快近百倍。该团队由吴恩达领导,他后来加入谷歌,再后来为百度效力(译者注:现在吴恩达已从百度离职)。突然之间,训练一个四层神经网络训练以前需要几周时间,现在只需要不到一天的时间。GPU制造商英伟达(NVIDIA)的老板黄仁勋(Jen-Hsun Huang)说,用来为玩家创造虚拟世界的芯片,也能用来帮助计算机通过深度学习技术理解现实世界,这体现了一种令人愉悦的对称性。
ImageNet Challenge的比赛结果证明深度学习大有可为。突然之间,人们开始对其给予巨大的关注,不只是在AI领域,还蔓延到整个技术界。此后,深度学习系统变得越来越强大:深度达到20或30层的网络不再罕见,微软的研究人员甚至构建了一个152层的网络。层数越多的网络具有更强的抽象能力,进而能够产生更好的结果。事实证明,这些网络善于解决非常广泛的问题。
“人们之所以对这个领域的进展感到如此兴奋,是因为作为学习技术之一的深度学习技术具有广泛的用途。”谷歌AI前主管也是现在谷歌搜索引擎负责人,约翰·詹南德雷亚(John Giannandrea)说。谷歌正在利用深度学习来提高其搜索结果的质量,以理解用户向智能手机发出的语音命令,帮助人们在特定影像中搜索他们需要的照片,自动进行电子邮件回复,改善网页翻译服务,以及帮助自动驾驶汽车识别周遭环境。
机器学习三大模式,学习如何学习
深度学习分很多种,其中使用最广泛的一种是“监督学习”(supervised learning),该技术利用标记样本来训练一个系统。以垃圾邮件过滤为例,这项技术可能会建立一个庞大的样本信息数据库,每条样本信息都会被标记为“垃圾邮件”或者“非垃圾邮件”。深度学习系统可以使用这种数据库进行训练,通过反复研究样本和调整神经网络内部的权值,改善垃圾邮件的识别准确率。这种方法的优点在于,不需要人类专家制定一套规则,也不需要程序员编写代码来实行规则。系统能够直接从标记数据中学习。
使用标记数据进行训练的系统被用来图像分类、识别语音、识别信用卡欺诈交易、垃圾邮件和恶意软件识别,以及定向投放广告。对于这些应用,正确的答案已经存在于先前的大量样本中。当你上传照片时,Facebook可以识别与标记你的朋友和家人。近期,该公司推出了一个系统,可以为盲人用户描述照片的内容(“两个人,微笑,太阳镜,户外,水”)。吴恩达说,监督学习能够应用于各种各样的数据。通过采用这项技术,现有的金融服务、计算机安全和营销领域的公司就可以给自己贴上AI公司的新标签。
另一种技术是非监督学习(unsupervised learning),同样是使用大量样本来训练系统,但不会告知其机器学习的目的。取而代之的是让神经网络在学习中识别特征和聚类相似样本,进而发现数据中隐藏的集合、链接或模式。

非监督学习可以用来搜索未知的东西,比如监控网络流量模式,找出可能与网络攻击有关的异常现象,或者检查大量的保险索赔以揭露新的欺诈手法。一个著名的例子是,2011年在谷歌工作时,吴恩达领导了一个名为Google Brain的项目。在这个项目中,一个巨大的无监督学习系统被要求在数千个非标记YouTube视频中寻找常见模式。一天,吴恩达的一位博士生给他带来了一个惊喜。“我记得他把我叫到他的电脑前,对我说‘瞧这个。’”吴恩达回忆道。屏幕上有一张毛茸茸的脸,那是从数千个样本中提取的图案。这个系统发现了猫。
强化学习(reinforcement learning)介于监督和非监督学习之间,只使用偶尔的反馈来训练神经网络与环境互动。从本质上讲,训练涉及调整网络的权值,并寻找一个持续产生更高回报的策略。DeepMind是这方面的行家。2015年2月,该公司在《自然》(Nature)杂志上发表了一篇文章,描述了一种强化学习系统,它能够学会玩49款雅达利经典的电子游戏,只使用屏幕像素和游戏得分作为输入数据,其输出数据与虚拟控制器连接。该系统学会了从头开始玩的所有游戏,并在29款游戏中都达到或超过了人类的水平。