本文翻译自英文原文的部分内容:A manifesto for Agile data science (2017 Agile data science 2.0 )
10年来,我一直从事着敏捷数据科学方面的工作——分析应用的迭代和进化式开发。起初,我还不知道该怎么称呼它。但当我作为一位全栈开发者独自工作的时候,迭代和进化我打造的分析软件就是再自然不过的事情了。加入一支团队后,我原以为也是这样。但实际上并非如此。
我还是网站开发人员的时候,就接触过敏捷方法,所以走上作为数据科学家的第一个工作岗位时,我吃惊地发现,数据科学并不敏捷。上任后的最初几周里,我拟定了一个复杂的预测系统,然后交付给其他人,但后者却需要6个月时间进行开发,然后才能交付使用。这违背了我对软件开发过程所知的一切,但鉴于那个系统的规模和大数据工具的状况,这个过程是必要的。该项目差点失败,在最后时刻才化险为夷。那段时间,我睡眠严重不足,但也积累了很重要的经验。
我不想再经历一次那样的痛苦了。于是,我试图让数据科学变得敏捷,并取得了不同程度的成功。当我开始把敏捷软件开发的方法应用于数据科学时,我发现了一个模式。但困难之处不在于具体实现,而在于处理数据(不只是软件)时要考虑实现敏捷的机会。
在多家公司工作的经历使我的想法逐渐成形,“敏捷数据科学宣言”就此诞生。宣言专注于如何思考,而不是该做什么。看板管理(Kanban)或Scrum方法的特性也适用于数据科学,前提是开发团队能够动态地思考数据探索过程中出现的机会。约翰·阿克雷德(John Akred)在敏捷数据科学的具体实现方面做了很有意义的研究,但就如何追踪工作而言,我有自己的一些看法——关键是要以积极和动态的方式看待数据科学。
敏捷数据科学宣言
迭代,迭代,迭代
洞见只有在经过连续几十次的检索才会涌现,别指望第一次就能有所发现。数据表必须经过分析、格式化、分类、集合和总结,才能被理解。通常要到第三次或者第四次尝试才能得出具有深刻见解的图表,而不会是第一次。若想建立准确的预测模型,需要经过特征工程和超参数调节的多次迭代。在数据科学中,迭代是洞见获取、可视化和产品化的基本要素。想构建产品就必须进行迭代。

交付中间产品
迭代是构建分析应用的必要之举,这意味着我们在最后的冲刺阶段常常会发现东西还不够完善。如果我们到了这个阶段还没有交付过半成品或中间产品,那么最后也常常就会没有任何东西可交付。这不能被称为敏捷,我称之为“死循环”——浪费无数的时间用于完善没人想要的东西。
好的系统是自文档化的,在敏捷数据科学中,我们在工作中记录和分享不完整的资产。我们完全致力于源代码管控。我们尽可能快地跟同事乃至终端用户分享工作成果。这个原则并不是对所有人都显而易见。很多拥有学术背景的数据科学家,多年的努力研究最终变成了一篇为了拿到学位而写的学术论文。

开展实验,而不是执行任务
在软件工程中,产品经理会在冲刺期间把一张图表交给开发人员去实现。这位开发人员会把任务转换成一个SQL GROUP BY,并制作出一个网页。任务完成了?错。以这种方式拟定的图表不可能有价值。数据科学不同于软件工程,因为它兼具科学和工程学的性质。
在任何特定的任务中,我们必须通过迭代以获得洞见,实验是对这些迭代的最好诠释。管理一支数据科学团队相当于管理多个同时发生的实验,而不是分派任务。好的资产(图表,报告,预测)是探索性数据分析的产物,因此我们必须从实验而不是任务的角度来思考问题。
倾听数据的声音
可能性与目标性同等重要。知道什么容易、什么困难,与期望一样重要。在软件应用开发中,有三个视角需要考虑:客户的视角,开发人员的视角,企业的视角。在分析应用开发中,还有另一个视角:数据的视角。如果不了解数据对产生特征的“看法”,产品的使用体验就不会很好。数据的“意见”必须始终囊括进产品讨论中,这意味着产品讨论必须根植于解释数据分析的可视化方案,而在内部测试版中也应当成为我们努力的焦点。
用数据价值金字塔让价值增量
数据价值金字塔(下图)是一个基于马斯洛需求层次理论的五级金字塔。它描述了将原始数据精炼成图表、报告和预测时创造出来的价值增量。不管是记录还是预测,都是为了促成新的行动,或者改善现有的行动:
- 数据价值金字塔的第一级(记录)是管道工程:让数据从收集处流向在应用中出现的位置。
- 第二级(图表)开始精炼和分析。
- 第三级(报告)是对数据的深入探索,以让我们真正弄懂数据背后的含义。
- 第四级(预测)创造了更多的价值,但准确的预测依赖于更低层级所包含和促成的特征工程。
- 最后一级(行动)是人工智能(AI)大放异彩的地方。如果你的洞见无法促成新的行动或者改善现有的行动,就没有多大价值。
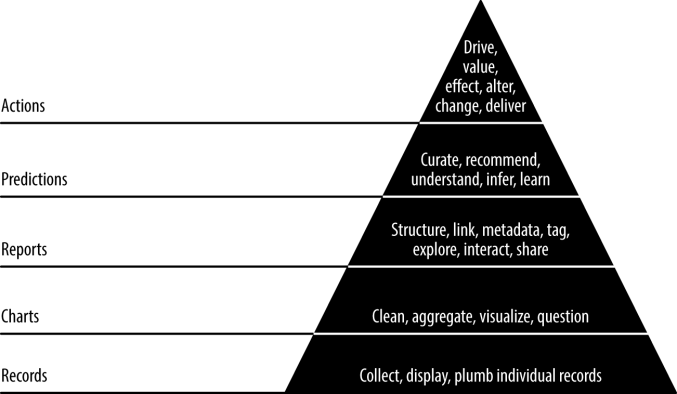
数据价值金字塔给予了我们工作的框架。这个金字塔是我们应该记住的东西,但不是严格遵循的原则。有时可以跳过一级,有时可以后退一级。如果你把一个新的数据集作为特征直接放入预测模型,但没有添加进更低层级的应用数据模型中以使得该数据集透明并可访问,那么你就会欠下技术债。你应该牢记:一有机会就要纠正上边的错误。
找到改善的关键路径
为了尽量提高成功的概率,我们应该把大多数时间用于影响成功最重要的方面。但哪些方面对成功最重要?这必须通过实验来发现。对产品开发的分析是对变动的产品目标的搜索和追求。
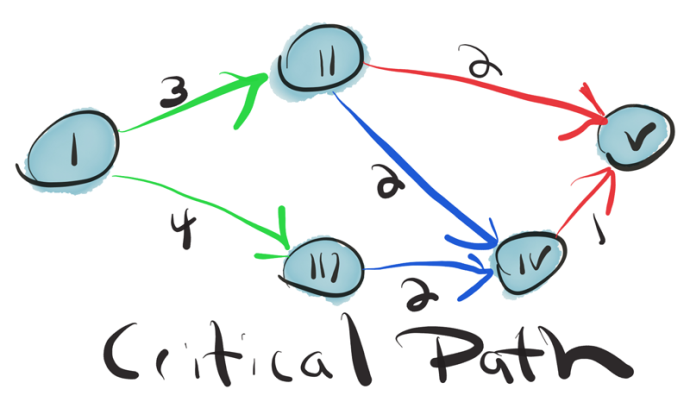
一旦确定目标,比如要做出一个预测,我们就必须找到实现的关键路径。如果这一路径被证明是有价值的,还必须找到改善的关键路径。在从一个任务流向另一个任务的过程中,数据被一步步精炼了。分析产品常常需要多个阶段的精炼,包括运用ETL(提取,转换,加载)过程、统计技巧、信息访问,机器学习,人工智能和图形分析等阶段。
这些阶段的相互联系构成了复杂的网络。团队领导者要时刻牢记这一网络,他的职责就是确保团队发现关键路径,然后组织团队落实路径。产品经理无法自上而下地管理这一过程,而是必须由产品科学家自下而上地发现它。
获得元,寻找杀手级产品
如果不能像开发普通的应用那样,轻松地按时交付好的产品,那我们交付什么?如果什么也交付不了,就不能号称“敏捷”。为了解决这个问题,在敏捷数据科学中,我们应该“获得元”。我们的重点是记录分析过程,而不是寻求最终状态或者产品。这可以让我们在反复攀爬数据价值金字塔、寻找杀手级产品的关键路径时,变得更加敏捷,塑造可交付的中间产品。那么,产品从哪里来?来自面板。我们通过记录探索性数据分析,创造了这个面板。

上述7条原则共同驱动了敏捷数据科学方法,构成和记录了探索性数据分析过程,并将之转变成了分析应用。